InnoDB Flow Architecture
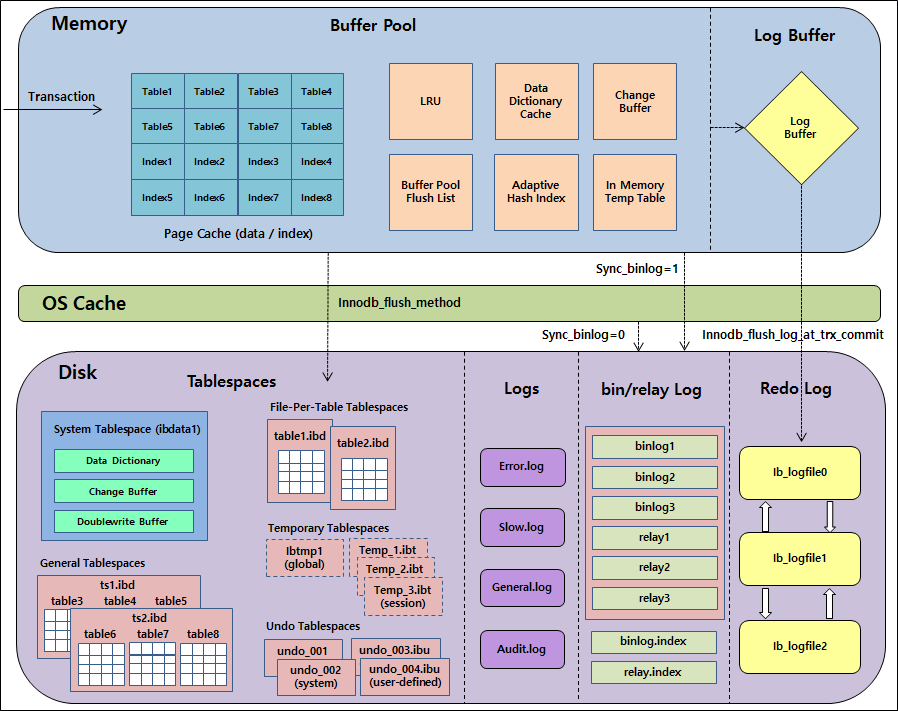
innodb_flush_method
- InnoDB가 Data File 과 Log File 로 데이터를 Flush 하는 방법
- 운영체제(OS)는 디스크에 데이터를 쓰는 작업을 운영체제의 버퍼로 기록하는 작업과 버퍼의 내용을 디스크로 복사하는 두 단계의 작업을 어떻게 조합하느냐에 따라 3가지 관점으로 쓰기 방식을 분류
- 첫번째 방식
- 동기(Sync) IO : 두 단계의 작업을 동시에 같이 실행하는 방식
- 비동기(Async) IO : 1단계와 2단계 작업을 각각 다른 시점에 실행하는 방식
- 두번째 방식
- 데이터가 변경되면 그와 동시에 파일의 변경 일시와 같은 메타 정보도 함께 변경하게 되는데..
- fsync : 데이터와 파일의 메타데이터를 한꺼번에 변경하는 방식
- fdatasync : 파일의 메타 정보는 무시하고 순수하게 사용자의 데이터만 변경하는 방식
- 세번째 방식
- Direct IO : 디스크 쓰기의 두 단계 작업 중에서 ‘운영체제의 버퍼 기록하는 작업’ 단계를 생략하고 바로 사용자의 데이터를 디스크로 쓰는 방식
- 첫번째 방식
1. fdatasync
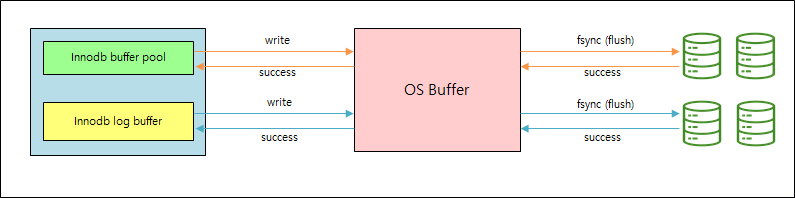
- O_DSYNC로 설정됐을 때와 동일하지만 파일의 메타 데이터는 변경하지 않게 하는 설정
- InnoDB는 fsync()를 사용해서 데이터 파일과 로그 파일을 모두 플러시하며 Double Buffering 유발 (I/O 증가)
2. O_DSYNC
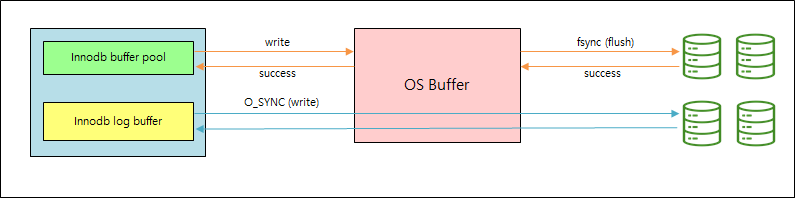
- 사용자 데이터와 메타 데이터까지 동기(Sync) IO 방식으로 기록하도록 설정
- InnoDB는 O_SYNC를 사용해서 로그 파일을 열고 플러시하지만 데이터 파일을 플러시하기 위해서는 fsync()를 사용
3. O_DIRECT
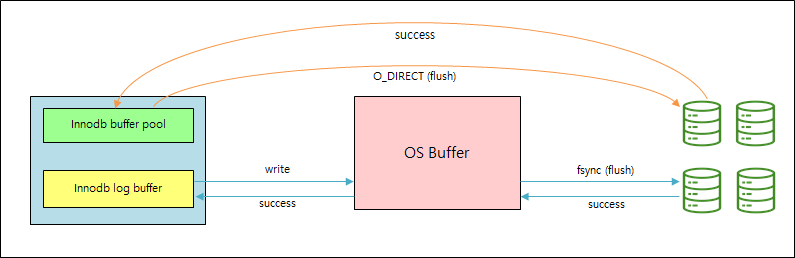
- 사용자 데이터와 메타데이터까지 동기(Sync) IO 방식으로 버퍼를 거치지 않고 설정
- InnoDB는 O_DIRECT를 사용해서 데이터 파일을 열고 데이터 파일과 로그 파일을 플러시하기 위해 fsync()를 사용
- O_DIRECT 사용하는 이유
- IO 성능 저하를 감안하고 더블버퍼링을 막아 메모리를 효율적으로 쓰기 위함
- InnoDB는 이미 버퍼풀(Buffer Pool)이라는 훨씬 고도화된 메모리 관리 영역을 가지고 있기 때문에 동일한 데이터를 버퍼풀과 OS캐시에 중복으로 저장해 메모리를 낭비할 필요가 없음
- 디스크로부터 읽혀지는 데이터는 운영체제의 캐시에 담아두고 다시 읽기 요청이 발생하면 디스크로부터 읽지 않고 캐시의 내용을 반환하는 형태로 성능을 개선하게 되지만, InnoDB는 운영체제의 캐시보다 더 체계적이고 효율적인 캐시 (InnoDB Buffer Pool)을 가지고 있기 때문에 운영체제의 캐시가 별로 도움이 되지 않음
<참고>
Double Buffering : 메모리상에서 buffer pool과 OS Cache에 중복으로 데이터를 저장하는 것
Double Write Buffer : 데이터의 안전성을 위해 디스크상에 중복된 데이터를 이중으로 저장하는 것
innodb_flush_log_at_trx_commit
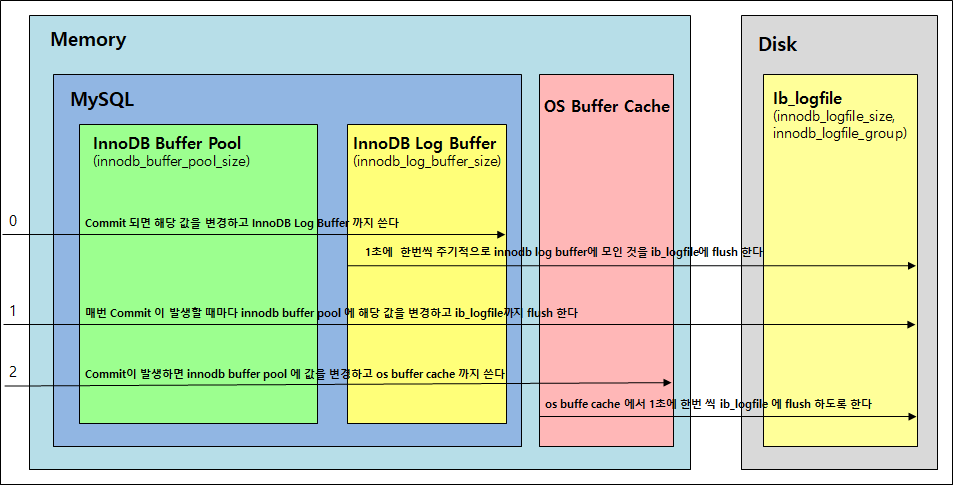
- InnoDB 에서 트랜잭션이 Commit 될 때마다 Redo를 디스크에 어떤 방식으로 Flush 할지 결정하는 옵션
- innodb_flush_log_at_trx_commit : 0
- Commit 시에 로그 버퍼를 로그 파일에 바로 기록하지 않고 1초 간격으로 Disk에 Flush
- Log Buffer 까지의 과정만 처리하고 1초에 한번씩 이후의 과정을 자동으로 수행하게 되는데 속도가 그만큼 더 빨라지지만 Commit 해도 최종적으로 Log Buffer에 쓰여지는 것 까지만 보장하므로 Flush 되는 과정에서 DBMS 가 Crash 되면 해당 트랜잭션은 유실됨
- innodb_flush_log_at_trx_commit : 1
- Commit 시에 로그 버퍼를 로그 파일에 기록하고 바로 Flush (기본값, ACID 준수를 위해 필요)
- 트랜잭션이 Commit 되면 일련의 과정을 건건이 처리하게 되는데 ACID 지속성을 보장할 수는 있지만 I/O 부하가 있음
- innodb_flush_log_at_trx_commit : 2
- Commit 시에 로그 버퍼를 로그 파일에 기록함. 디스크 플러시 작업은 초당 1회. 그러나 스케줄링 상황에 따라 반드시 초당 1회 동작한다는 보장은 없음
- 트랜잭션의 양은 상관없이 Flush 가 약 1초에 한번씩 자동 수행되기 때문에 매번 Flush 되는 기본값보다 I/O 성능이 좋아지지만 단점은 데이터를 유실할 가능성은 있음
- OS Buffer 까지는 데이터가 넘어가기 때문에 DBMS가 Crash 되는 건 별 문제가 없지만 1초 마다 실행되는 Flush가 실행되고 있는 와중에 OS 셧다운이 발생되버린다면 해당 트랜잭션은 Commit 되었지만 유실될 수 있음